
Making background jobs more resilient by default
When it comes to job processing, timing is everything. Running jobs in the background helps us remove the load from the web servers handling our customer's requests. However, we also want the background jobs to run in a reasonable amount of time for our customers. But what if a customer added so many background jobs that they used all of the background worker resources?
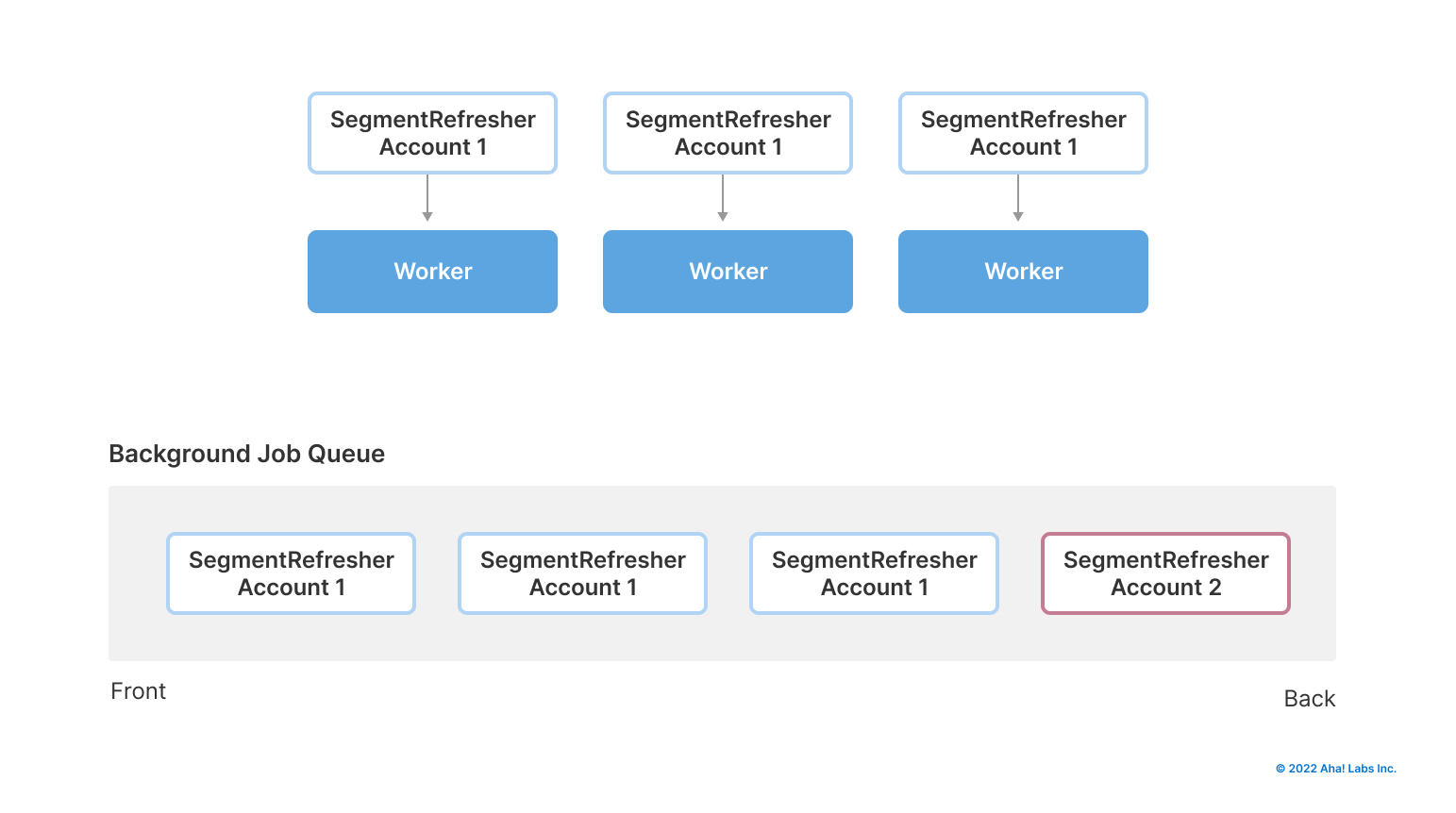
The jobs will be processed by available workers in the order they come in, which works great for the customer that added these jobs. But unfortunately for other accounts, their segments won't refresh until the backlog of all of those jobs is finished. This could be a problem for those accounts — it would look like the system isn't functioning properly as it waits for the queue to clear.
We have solved this problem at Aha! by creating a module that:
- Batches separate jobs together
- Limits the runtime of any single job
- Limits parallel processing
When a job utilizes this new module, it becomes resilient to this problem by default.
Let's explore this with an example to show how to prevent this slowdown for all accounts. Let's say we have Accounts with various Segments (i.e., "groups"). Whenever we update a Segment, we want to refresh that segment. This process could take a bit of time so we will put it into a background job. We may end up with some controller code that looks like this:
class SegementsController < ApplicationController
def update
segment = current_account.segments.find(params[:id])
segment.update!(segment_params)
SegmentRefresher.perform_later(segment)
head :ok
end
endIt is usually good to process what can be done immediately and then delay some of the more expensive work. This allows us to give immediate responses back to our customers and still perform the work that needs to be done. However, a customer could put thousands of SegmentRefresher jobs onto our background job queue and prevent other customers' jobs from running.
Batching separate jobs together
Typically, when a background job is enqueued via ActiveJob, the parameters for the job are passed in as arguments to perform_later. This isn't quite what we want in order to batch jobs together. Instead, we create a new method perform_batch_later that puts the arguments into a data store such as Redis from which the job can later retrieve them.
So previously the job code may have looked like the following:
class SegmentRefresher < ApplicationJob
def perform(segment)
# Refresh the segment
end
endWe now have something that looks like this:
module BatchByAccount
extend ActiveSupport::Concern
class_methods do
# Push the data into Redis and then enqueue the job
def perform_batch_later(data)
data.each_slice(100) do |slice|
Redis.current.rpush(data_key, slice.map(&:id))
end
perform_later
end
def self.data_key
"SegmentRefresher:#{Account.current.id}"
end
end
end
class SegmentRefresher < ApplicationJob
include BatchByAccount
def perform
segment_ids = Redis.current.lpop(self.class.data_key, 100)
Segment.where(id: segment_ids).each do |segement|
# Refresh the segment
end
end
endThe controller can now call SegmentRefresher.perform_batch_later with one or more Segments and that will be stored in Redis. Later, the job will run and grab 100 of those segment ids at a time to process.
This technique can be really powerful. It allows multiple processes to not know about the other and still batch the data together. Further, we can utilize different Redis methods to get slightly different behaviors. For example:
- Using
rpushto add records andlpopto remove them will give us a first in/first out queue. We can use this when the order of the jobs is important. - Using
spushto add records andspopto remove them will give us an unordered set. This means that duplicate data is automatically filtered out, which prevents unnecessary work from being done. However, it is unordered so the jobs may be processed in a different order than they were enqueued. - Using a timestamp and
zaddto add records andzrangebyscore/zremto remove them lets us create a delayed unordered set. This is useful for actions we want to perform in the future. This might show up if we want to perform an action five minutes after a customer stops interacting with an object.
Limiting the runtime of any single job
Now that we are batching data together, we want to limit how long a single job can run. In order to tackle this, we leveraged functionality from the job-iteration gem. This gem provides an interface where we can define an enumerator and what to do each iteration. The gem will handle the rest. Utilizing this, our job and module will now look like this: (For ease of reading, the bit of code already shown has been removed.)
module BatchByAccount
extend ActiveSupport::Concern
class_methods do
def perform_batch_later(data)
# ...
end
def self.data_key
# ...
end
end
included do
include JobIteration::Iteration
end
def build_enumerator(*)
Enumerator.new do |yielder|
# We will pull 100 records out of the queue at a time and yield that to the enumerator
while (segment_ids = Redis.current.lpop(self.class.data_key, 100)).any?
yielder.yield segment_ids, nil
end
end
end
end
class SegmentRefresher < ApplicationJob
include BatchByAccount
def each_iteration(segment_ids)
Segment.where(id: segment_ids).each do |segement|
# Refresh the segment
end
end
endNotice that the SegmentRefresher 's perform method has been swapped for an each_iteration method.
As long as there is data in Redis, this job will continue to perform until we hit the time threshold as defined by JobIteration.max_job_runtime. The default is five minutes. Once we hit the threshold, the job will be interrupted and will re-queue itself. This will ensure that even if it takes a long time to refresh all of the segments, it won't monopolize a worker.
Limiting parallel processing
Now that data is batched together and individual jobs are handling things in batches, we want to prevent race conditions of multiple jobs running at once. We solved this by using the activejob-uniqueness gem.
With this gem, we can make the jobs unique. Duplicate jobs for a single account will be ignored. Because there is only one job, we have to handle a race condition of what would happen if our one job finished at the same moment that new data is added.
The resulting job ends up looking like this:
module BatchByAccount
extend ActiveSupport::Concern
class_methods do
def perform_batch_later(data)
# ...
end
def self.data_key
# ...
end
end
included do
include JobIteration::Iteration
unique :until_expired, lock_ttl: 5.minutes
rescue_from(StandardError, with: :handle_error)
on_shutdown do
# Ensure than when we are interrupting the job, that we clear the lock so that it can be re-queued
lock_strategy.unlock(resource: lock_key)
end
on_complete do
if Redis.current.llen(self.class.data_key) > 0
# This is the race condition
# If we are complete, but there is still data in the queue, we need to enqueue a new job to process it
self.class.perform_later
end
end
end
end
def handle_error(exception)
# Ensure we unlock the job on error
lock_strategy.unlock(resource: lock_key)
raise exception
end
# These arguments can be tweaked or overridden to lock on different criteria or allow
# some amount of parallelism
def lock_key_arguments
[Account.current.id]
end
def build_enumerator(*)
# ...
end
end
class SegmentRefresher < ApplicationJob
include BatchByAccount
def each_iteration(segment_ids)
# ...
end
endResiliency by default
The job itself barely changed but it is now more resilient. By creating some easy-to-reuse patterns, engineers can focus more on their own features instead of worrying about common resiliency problems. We can put energy into making the right choice easy for everyone.
The final code will look like this:
module BatchByAccount
extend ActiveSupport::Concern
class_methods do
def perform_batch_later(data)
data.each_slice(100) do |slice|
Redis.current.rpush(data_key, slice.map(&:id))
end
# If the job is already enqueued or running, this will be a no-op
perform_later
end
def self.data_key
"SegmentRefresher:#{Account.current.id}"
end
end
included do
include JobIteration::Iteration
unique :until_expired, lock_ttl: 5.minutes
rescue_from(StandardError, with: :handle_error)
on_shutdown do
# Ensure than when we are interrupting the job, that we clear the lock so that it can be re-queued
lock_strategy.unlock(resource: lock_key)
end
on_complete do
if Redis.current.llen(self.class.data_key) > 0
# This is the race condition
# If we are complete, but there is still data in the queue, we need to enqueue a new job to process it
self.class.perform_later
end
end
end
end
def build_enumerator(*)
Enumerator.new do |yielder|
while (segment_ids = Redis.current.lpop(self.class.data_key, 100)).any?
yielder.yield segment_ids, nil
end
end
end
def handle_error(exception)
# Ensure we unlock the job on error
lock_strategy.unlock(resource: lock_key)
raise exception
end
# These arguments can be tweaked or overridden to lock on different criteria or allow
# some amount of parallelism
def lock_key_arguments
[Account.current.id]
end
end
class SegmentRefresher < ApplicationJob
include BatchByAccount
def each_iteration(segment_ids)
Segment.where(id: segment_ids).each do |segement|
# Refresh the segment
end
end
endSign up for a free trial of Aha! Develop
Aha! Develop is a fully extendable agile development tool. Prioritize the backlog, estimate work, and plan sprints. If you are interested in an integrated product development approach, use Aha! Roadmaps and Aha! Develop together. Sign up for a free 30-day trial or join a live demo to see why more than 5,000 companies trust our software to build lovable products and be happy doing it.


